

Why AI/ML/Data Projects Can't Be Agile
Incremental and Iterative way of development isn't effective here

Recently one of my LinkedIn connection pondered on LinkedIn:

The problem description is a good one except the last line:
How do we solve this?
Whenever we ponder, “How do we solve this?” we are assuming the following:
The Problem need to be solved
The Problem can be solved
So this post is on:
Does AI/ML/Data projects need to be Agile?
Can AI/ML/Data projects be Agile?
Ask a Manager:
Whether a Project needs to be Agile?
There is near 100% probability that the answer will be:
Heck Yes!
Why is that so?
The space of Enterprise Agile is so polluted with perennial wartime urgency that the resounding answer universally implies:
Doing something in short deadline - produce output by two week sprint.
Benjamin Franklin once stated:

But often in chaotic Information Technology space exactly that is what happens - some Output is often produced by the end of an Agile Sprint which is assumed to lead to desired Outcome - sooner or later. So we have answer to our first question:
Does AI/ML/Data projects need to be Agile?
Who do you think can say No?
If you think a little deeper, Agile is like a Credit Card. It allows you to spend without thinking of budgets. Spend something to get something. Live in the Now …
Since we just answered first question:
Does AI/ML/Data projects need to be Agile?
rest of this post, attempts to answer the next question:
Can AI/ML/Data projects be Agile?
The finding of this post seem to suggest the answer is:
Most definitely not
First lets start with how the Tree Of Knolege evolves over time. We start with sensory perception and experience the world. In order to make higher sense from raw senses, we need to evolve theory. So we have a first version of a Theory which we put to Practice. Over time practice informs us shortcomings of v1 theory since human nature is to always seek improvement. This quest to do better always leads to second iteration of the theory. As you know, General Theory of Relativity (v2) was needed since Special Theory of Relativity (v1) was based on uniform velocity. We could not ignore acceleration and thus had to invet v2 theory of motion.
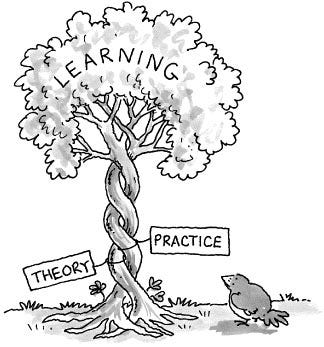
This forces us the example the state of Theoretical Machine Learning and compare it to Theoretical Computer Science. Design of algorithms and machines capable of “intelligent” comprehension and decision making is one of the major scientific and technological challenges of this century. It is also a challenge for mathematics because it calls for new paradigms for mathematical reasoning, such as formalizing the “meaning” or “information content” of a piece of text or an image or scientific data. It is a challenge for mathematical optimization because the algorithms involved must scale to very large input sizes. It is a challenge for theoretical computer science because the obvious ways of formalizing many computational tasks in machine learning are provably intractable in a worst-case sense, and thus calls for new modes of analysis.
Unfortunately most of the theory behind Machine Learning (leading to Artificial Intelligence) is quite black box as of now. To cite an evidence, here is a in-development book:
This monograph discusses the emerging theory of deep learning. It is based upon a graduate seminar taught at Princeton University in Fall 2019 in conjunction with a Special Year on Optimization, Statistics, and Machine Learning at the Institute for Advanced Study. Much of the book so far concerned supervised learning.
Theoretical results in machine learning mainly deal with a type of inductive learning called supervised learning. In supervised learning, an algorithm is given samples that are labeled in some useful way. For example, the samples might be descriptions of mushrooms, and the labels could be whether or not the mushrooms are edible. The algorithm takes these previously labeled samples and uses them to induce a classifier. This classifier is a function that assigns labels to samples, including samples that have not been seen previously by the algorithm. The goal of the supervised learning algorithm is to optimize some measure of performance such as minimizing the number of mistakes made on new samples.
Therein lies a massive weakness of AI/ML industrialization. Supervised learning comes with the baggage of bias ingrained of supervisors. Why do you think the Internet is biased towards Western Culture? That is because the Internet (and the Data it generates) was invented in the Western Hemisphere! Since most of AI/ML is black box, we cannot reliably trust Unsupervised Learning - it is at its infancy. But without the infrastructure of Unsupervised Learning, we cannot develop Artificial General Intelligence (AGI). AGI is the best and trustworthy replacement for Humans - the holy grail. This holy grail seems to be out of reach given our current state of knowledge about knowledge development.
We leave this section with the unmistakable impression that Computational Learning Theory has much scope of advancement and is quite immature compared to Theory and Practice of Computing.
Look at the illustration of progressve (25% - 50% - 100%) image download below:

In this simple illustration lies two powerful coneptuatal underpinning of Agile:
Incremental
Iterative
Under Incremental paradigm, we download the one fourth of the full resolution photo, followed by half and followed by full. In this paradigm the big picture is not clear from the outset but whatever is Done is Done-Done, i.e. high quality and no rework needed.
Under Iterative paradigm, we download the full picture with one fourth of pixels, followed by half and followed by all. In this paradigm the big picture may not be crystal clear from the outset but focus is on end-to-end delivery.
Typically Agile implementation emphasizes Iterative modus operandi with some Incrementalism thrown in. So if we would like to answer the following question:
Can AI/ML/Data projects be Agile?
We need to analyze whether AI/ML/Data projects allow for Iterative and Incremental divide and conquer.

I tried to search for images for Retrograde Amnesia. Retrograde amnesia is the inability to remember past events or experiences. People with retrograde amnesia remember events today but may not remember memories that occurred before the event that caused the amnesia. Retrograde amnesia usually affects more recently stored memories than older memories.